
Pattern 5 (Case Data)
FLASH animation of Case Data pattern
Description
Data elements are supported which are specific to a process instance or case. They can be accessed by all components of the process during the execution of the case.
Example
The employee assessment results can be accessed by all of the tasks during this execution instance of the Performance Assessment workflow.
Motivation
Data elements defined at case level effectively provide global data storage during the execution of a specific case. Through their use, data can be made accessible to all process components without the need to explicitly denote the means by which it is passed between them.
Overview
Figure 6 illustrates the use of the case level data element X which is utilised by all of the tasks throughout a process (including those in subprocess).
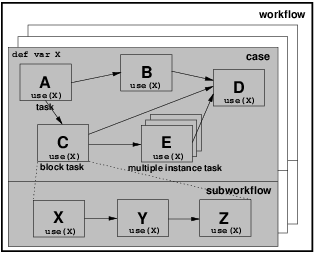
Figure 6: Case level data visibility
Context
There are no specific context conditions associated with this pattern.
Implementation
Most workflow engines support the notion of case data in some form, however the approaches to its implementation vary widely. Staffware implements a data management strategy that is based on the notion of a common data store for each workflow case although individual data fields must be explicitly passed to subprocesses in order to make them accessible to the tasks within them. Websphere MQ takes a different approach with a global data store being defined for each workflow case for case level data elements but distinct data passing conventions needing to be specified to make this data accessible to individual tasks. COSA provides a series of types of data constructs with the INSTANCE tool agent corresponding to case level data elements which are globally accessible throughout a workflow case (and associated subprocesses) by default. BPMN supports case data through the Properties attribute of a process. In FLOWer, XPDL and BPEL, the default binding for data elements is at case level and they are visible to all of the components in a process. UML 2.0 ADs do not support case data (or folder data) as all instances of a process appear to execute in the same context.
Issues
One consideration that arises with the use of case level data is in ensuring that these elements are accessible, where required, to the components of a subprocess associated with a specific case (e.g. as the definition of a block task).
A second issue associated with the use of case level data is that of managing concurrent access to it by multiple process instances.
Solutions
The first issue is addressed in one of two ways. In some PAIS, subprocesses that are linked to a process model do not seem to be considered to be part of the same execution context as the main process. To remedy this issue, tools such as Staffware and WebSphere MQ require that case level data elements be explicitly passed to and from subprocesses as parameters in order to make them visible to the various components at this level. Alternatively PAIS can make these data elements visible to all subprocesses by default, as is the situation in COSA, FLOWer and XPDL.
There are not clear cut solutions to the second issue. Concurrency management is not an area that is currently well-addressed by commercial PAIS offerings. Where an offering provides for case level data, the general solutions to the concurrency problem tend to be either to allow for the use of a third party transaction manager (e.g. Staffware which allows Tuxedo to be used for transaction management) or to leave the problem to the auspices of the development (e.g. COSA).
There has been significant research interest in the various forms of advanced transaction support that are required for business processes [Gre02, RS95, AAA+96, WS97, DHL01] and several prototypes have been constructed which provide varying degrees of concurrency management and transactional support for workflow systems e.g. METEOR [KS95], EXOTICA [AAA+96], WIDE [GVA01], CrossFlow [VDGK00] and ConTracts [WR92], although most of these advances have yet to be incorporated in mainsteam commercial products.
Evaluation Criteria
An offering achieves full support if it has a construct that satisfies the description for the pattern. It achieves a partial support rating if case data elements must be explicitly passed to and from subprocesses.
Product Evaluation
To achieve a + rating (direct support) or a +/- rating (partial support) the product should satisfy the corresponding evaluation criterion of the pattern. Otherwise a - rating (no support) is assigned.
Product/Language |
Version |
Score |
Motivation |
|---|---|---|---|
| Staffware | 9 | +/- | Main workflow procedure can maintain data fields for each case but they must be explicitly passed to sub-workflows |
| Websphere MQ Workflow | 3.4 | + | Supported through the default data structure |
| FLOWer | 3.0 | + | Default binding for a data element |
| COSA | 4.2 | + | Supported via tool agent INSTANCE (INSTANCE.name). |
| XPDL | 1.0 | + | A workflow process can have "data elements. In case of nesting the scope is not 100% clear |
| BPEL4WS | 1.1 | + | The default scoping for variables is process level |
| BPMN | 1.0 | + | Supported through the attribute Properties of a Process |
| UML | 2.0 | - | Not supported |
| Oracle BPEL | 10.1.2 | + | Bound to outermost scope in the process definition |
| jBPM | 3.1.4 | + | In jBPM the common approach to characterising data elements is via process variables. |
| OpenWFE | 1.7.3 | + | In OpenWFE, all data elements are globally accessible throughout a process instance and, once defined, all fields are visible (unless restricted by the use of filters) to all subsequent tasks in a process instance. Hence OpenWFE directly supports the Case Data pattern. |
| Enhydra Shark | 2 | + | Enhydra Shark supports case data through workflow level variables and package level variables. |
Summary of Evaluation
+ Rating |
+/- Rating |
|---|---|
|
|